When you check in to a hotel, you are usually greeted by a receptionist.
The receptionist takes care of checking your documents, making some data entries in their system and directing you to a specific room.
Load balancers do a similar job within a system.
It’s a type of hardware or software tool that distributes incoming network traffic across multiple servers.
Check out the below high-level diagram that shows where the load balancer actually resides.
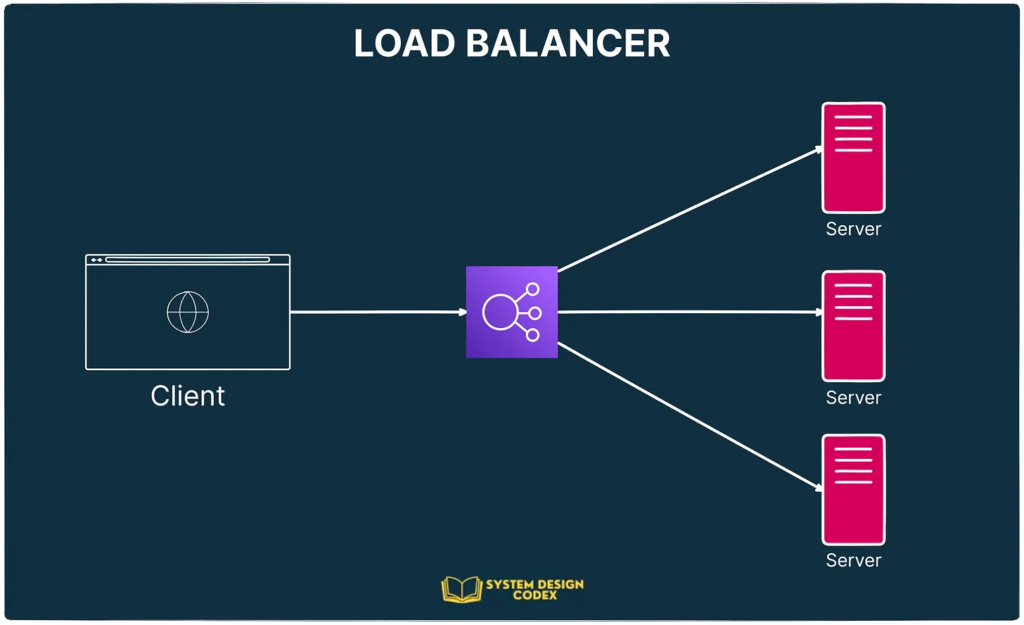
Of course, it might appear simple, which is definitely a good thing. Engineers can just plug it in within their system and it acts like a black-box doing its job.
However, there are several aspects to a load balancer that software engineers must be aware of in order to use it effectively for their application needs.
In this post, I will cover the following points:
- The need for Load Balancers
- Types of Load Balancers
- Load Balancing Algorithms
- Making Load Balancers Highly-Available
The Need for Load Balancers
A few years ago, I was working on a design for a brand-new system that was meant to generate customer reports.
The manager walked by and he noticed the word “LB” scribbled on a box on my whiteboard. Being a curious fellow, he asked me why we needed to invest in another component.
In his defense, cost was a big concern back then.
But Load Balancers weren’t something that I was going to skimp on. It was basically the most important part of the whole setup.
But somehow, I had to get the point across to the manager and the ultimate decision-makers.
I provided two important reasons:
1 – Workload Distribution
The high-traffic application that we were building had to serve thousands of concurrent requests.
There was no way we could rely on a single machine and to make things manageable, we went for horizontal scaling.
Horizontal Scaling (also known as scaling out) is a technique to increase the capacity of a service by adding more machines to do the job.
More capacity means the ability to handle a greater workload
“But I still don’t understand the need for a Load Balancer,” the manager said.
That’s when I explained that adding machines is just one part of the equation.
You also need to make sure that all the machines share the load appropriately and that no single machine gets overwhelmed. That’s where the load balancer comes into the picture.
“Just like you take care of every developer in the team,” I added.
I suppose that last statement made a good impact.
2 – Redundancy
But as I said, my manager was quite curious.
“I understand we need multiple machines and workload sharing. But we can manage that manually. Joe is anyways on-call”
This is where I pulled out my main point.
For a professional system, availability is an important metric. High availability just takes the concept of availability to an even higher level.
In typical terms, a server must have 99.999% uptime to be considered highly available.
But how do we achieve these crazy numbers?
By removing any single point of failure (SPOF) within the infrastructure or software layer.
For example, if you have a backend service handling requests, you run multiple instances of the service to share the workload. But if one instance goes down for whatever reason, the service as a whole continues running because the load balancer will make sure that the requests always go to the healthy instances.
Doing all of this manually would be a nightmare. Plus, there are bound to be disgruntled users.
“You don’t want to build an unprofessional system in your name, boss!”
I suspect it was the last statement that sealed the deal.
Types of Load Balancers
“Will you go for Layer 4 or Layer 7 load balancer?”
This was the question that took me down a rabbit hole.
It came up during a team discussion when I was just starting as a software engineer.
Someone had just drawn a box named “LB” on the whiteboard and another team-mate asked this question.
“Layer 4 or Layer 7?”
As I went through the details, thing became clearer:
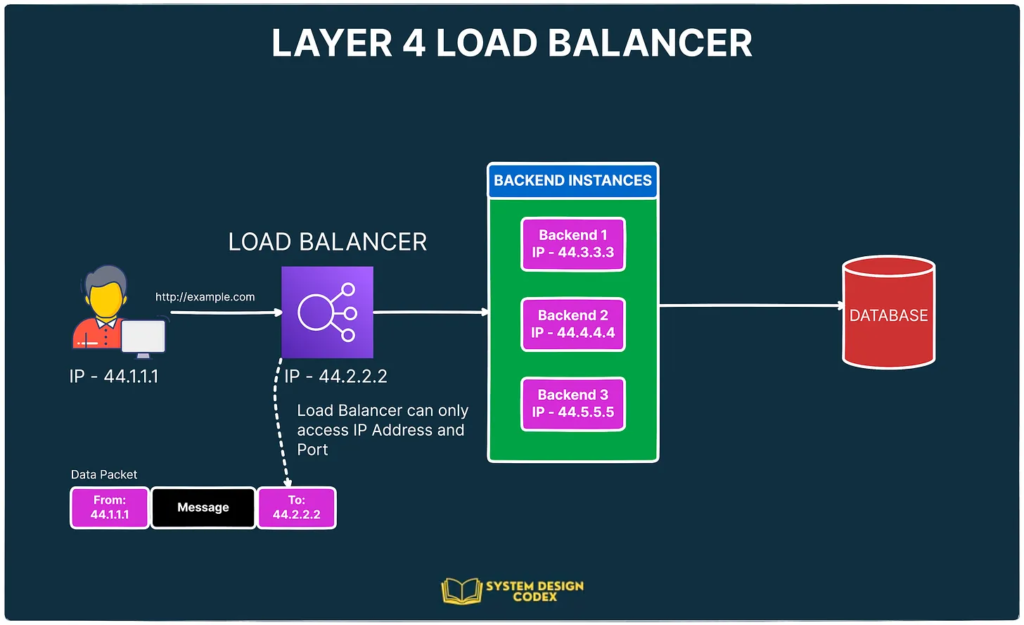
1 – Layer 4 Load Balancer
As the name suggests, Layer 4 load balancers operate in the transport layer of the OSI model.
Yes, the famous OSI model from Computer Networks!
What does it mean?
It means that the load balancer makes routing decisions solely on the basis of information available at Layer 4.
Information such as IP address or port.
In other words, a Layer 4 load balancer cannot see the message in the data packet.
Here’s what it looks like:
Advantages of Layer 4 load balancers:
- It’s simpler to run and maintain
- Better performance since no data lookup
- More secure since there’s no need to decrypt the TLS data
- Only one TCP connection
Disadvantages:
- No smart load balancing
- No routing to different service types
- No caching since the LB can’t even see the data or the message.
Examples of Layer 4 load balancers are HAProxy, AWS Network Load Balancer, Azure Load Balancer and so on.
2 – Layer 7 Load Balancer
Layer 7 load balancers operate at layer 7 of the OSI model.
That was predictable, I suppose.
Basically, this means they deal with layer 7 protocols such as HTTP(S), WebSocket, FTP, and SMTP.
But what does that change?
The Layer 7 load balancers can see the actual data within the packet and make routing decisions based on that data.
See the below illustration:
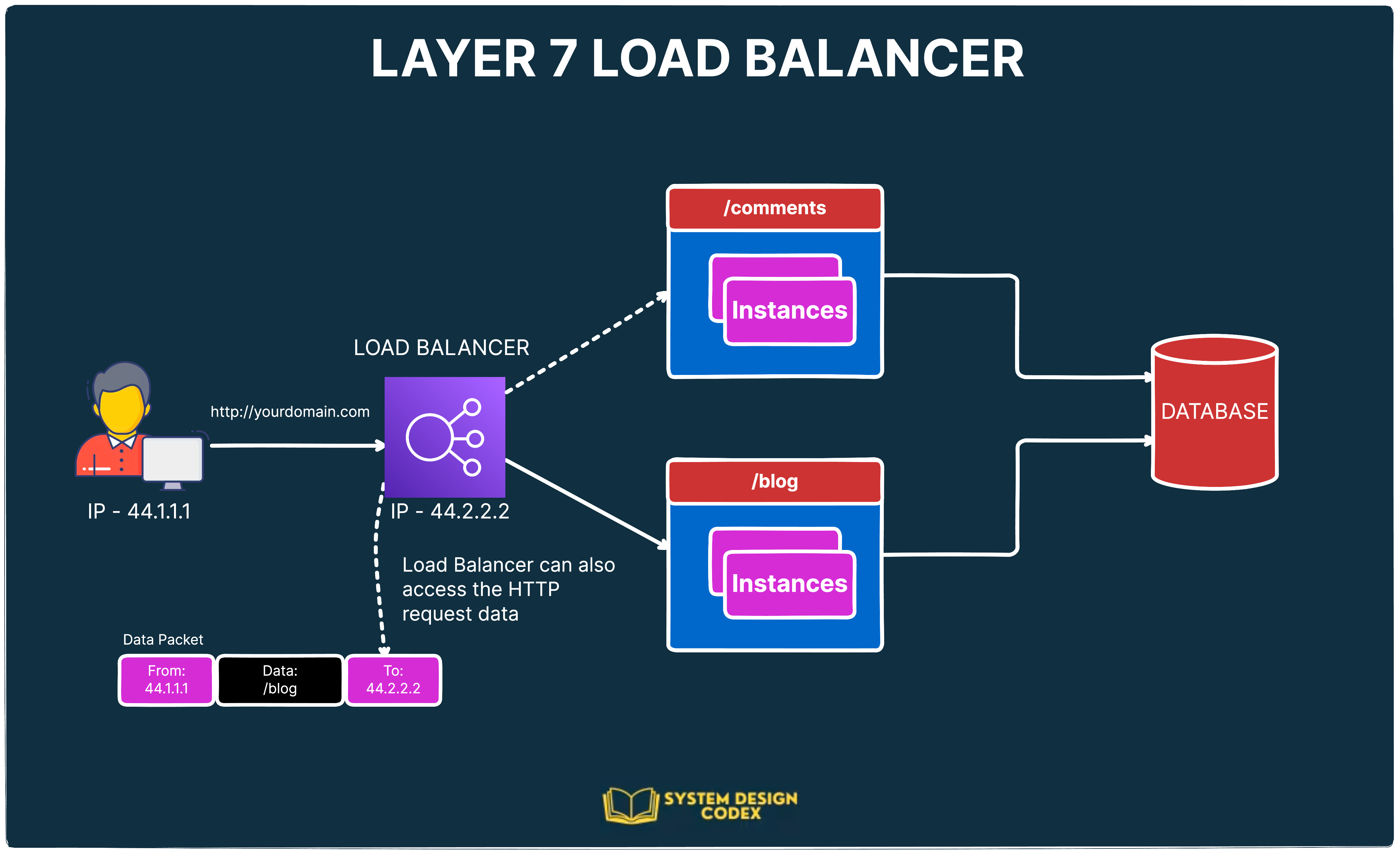
Here’s how Layer 7 load balancers work:
- Let’s say you have two microservices – one dedicated to the blog posts (
/blog) and the other dedicated to the comments (/comments). - The client makes a request to the load balancer by establishing a TCP connection, saying that it wants to access the
/blogroute. - The load balancer decrypts the data and checks the configured rules.
- Based on the request destination, the load balancer establishes a new TCP connection to the server instances hosting the Blog microservice.
- Once the response comes back, it sends over the response to the client.
Advantages:
- Smarter load balancing (big benefit)
- LB can also cache data
- Can play the role of a reverse proxy
Disadvantages:
- Expensive to run and maintain
- Needs to decrypt the data
- Maintains 2 TCP connections – one from the client to the load balancer and another from the load balancer to the service
Examples of Layer 7 load balancers include HAProxy, Nginx, AWS Application Load Balancer and Azure Application Gateway.
Load Balancing Algorithms
By now, it should be quite clear that load balancers are great at distributing a bunch of requests among multiple servers.
But how do load balancers determine which request should go to which particular server?
It all depends on the load balancing algorithm being used.
Broadly, you can divide these algorithms into two categories:
- Static
- Dynamic
Static Load Balancing Algorithms
The static algorithms distribute traffic among servers based on pre-determined rules or fixed configuration.
To put things simply, these algorithms don’t adapt to changing server workloads.
A few popular static load balancing algorithms are as follows:
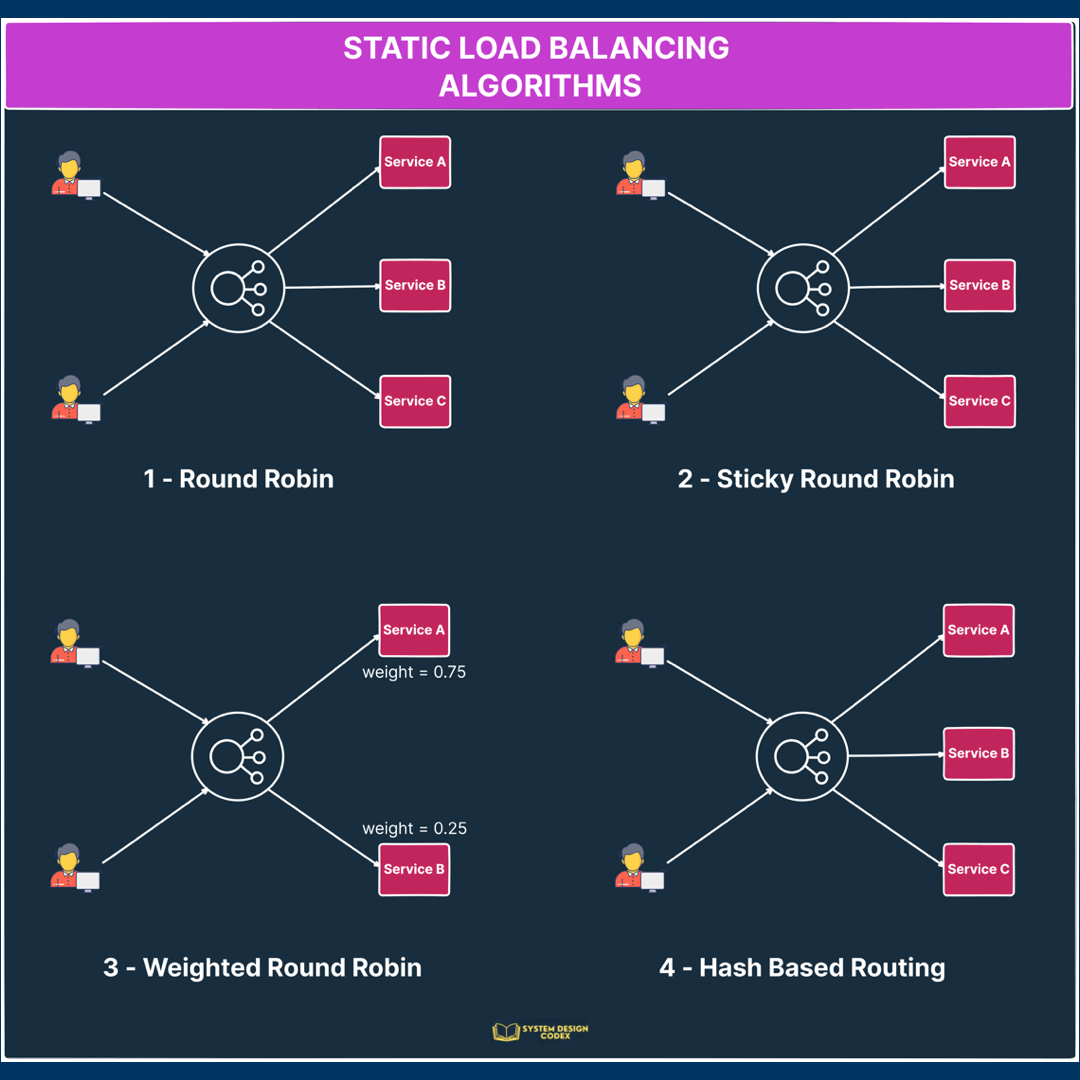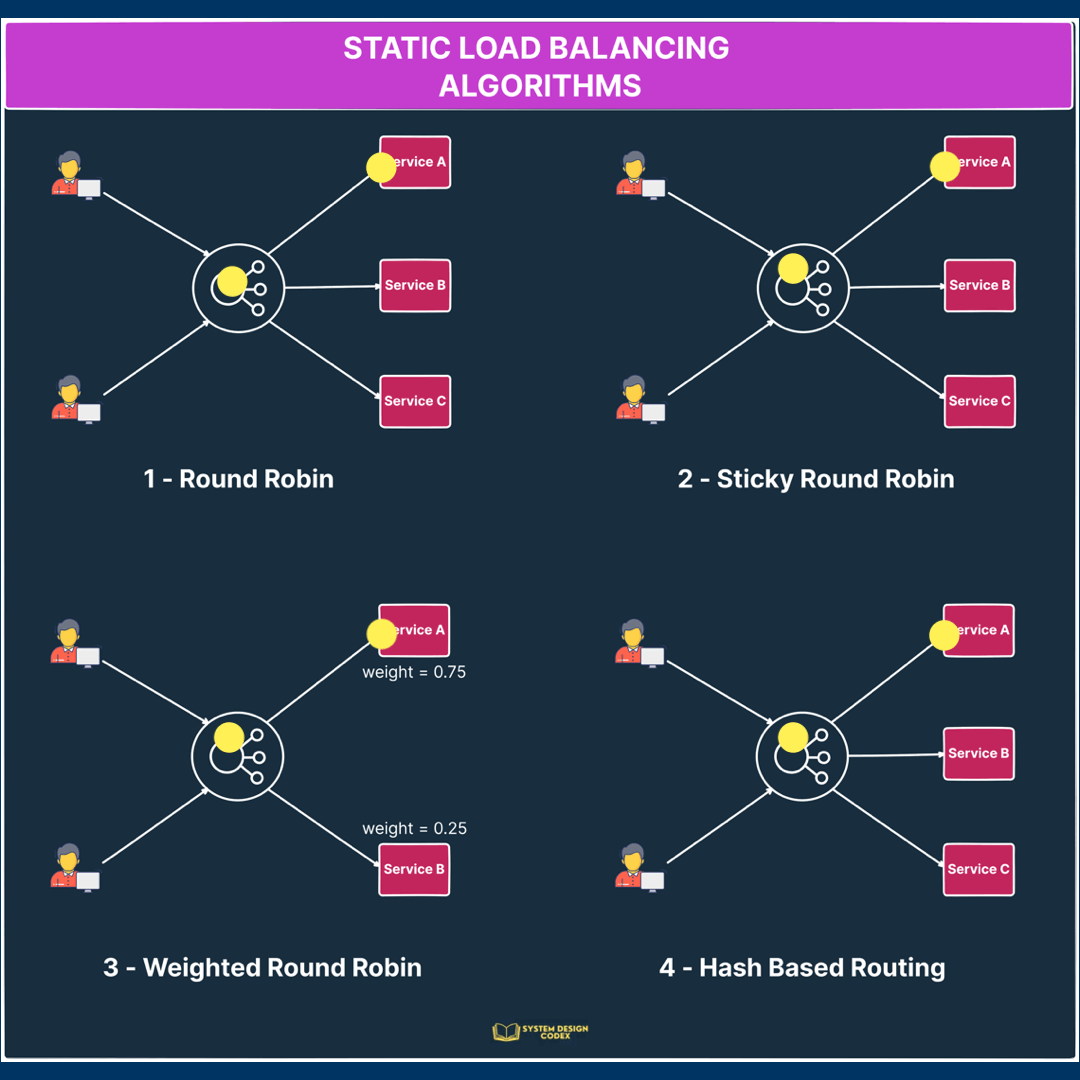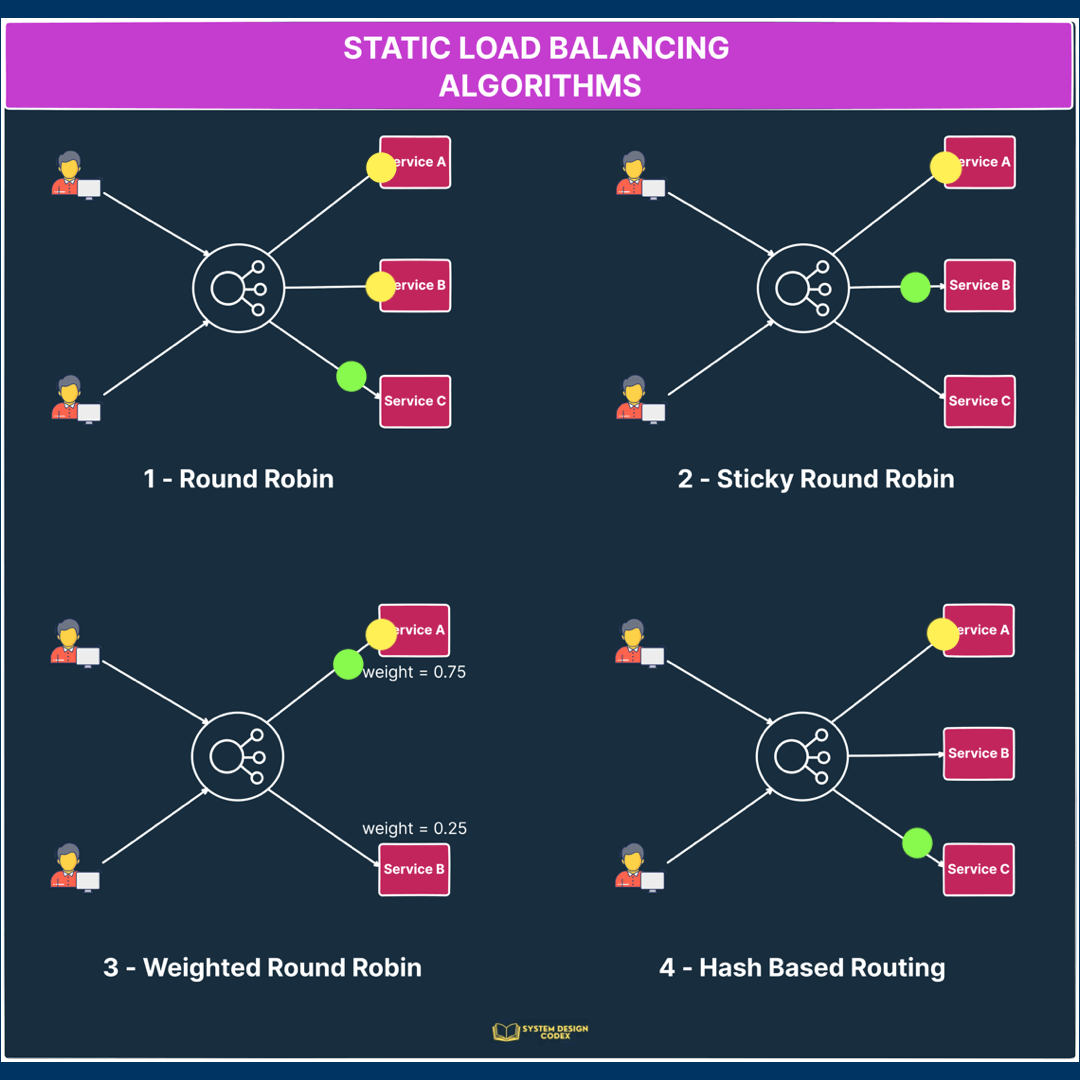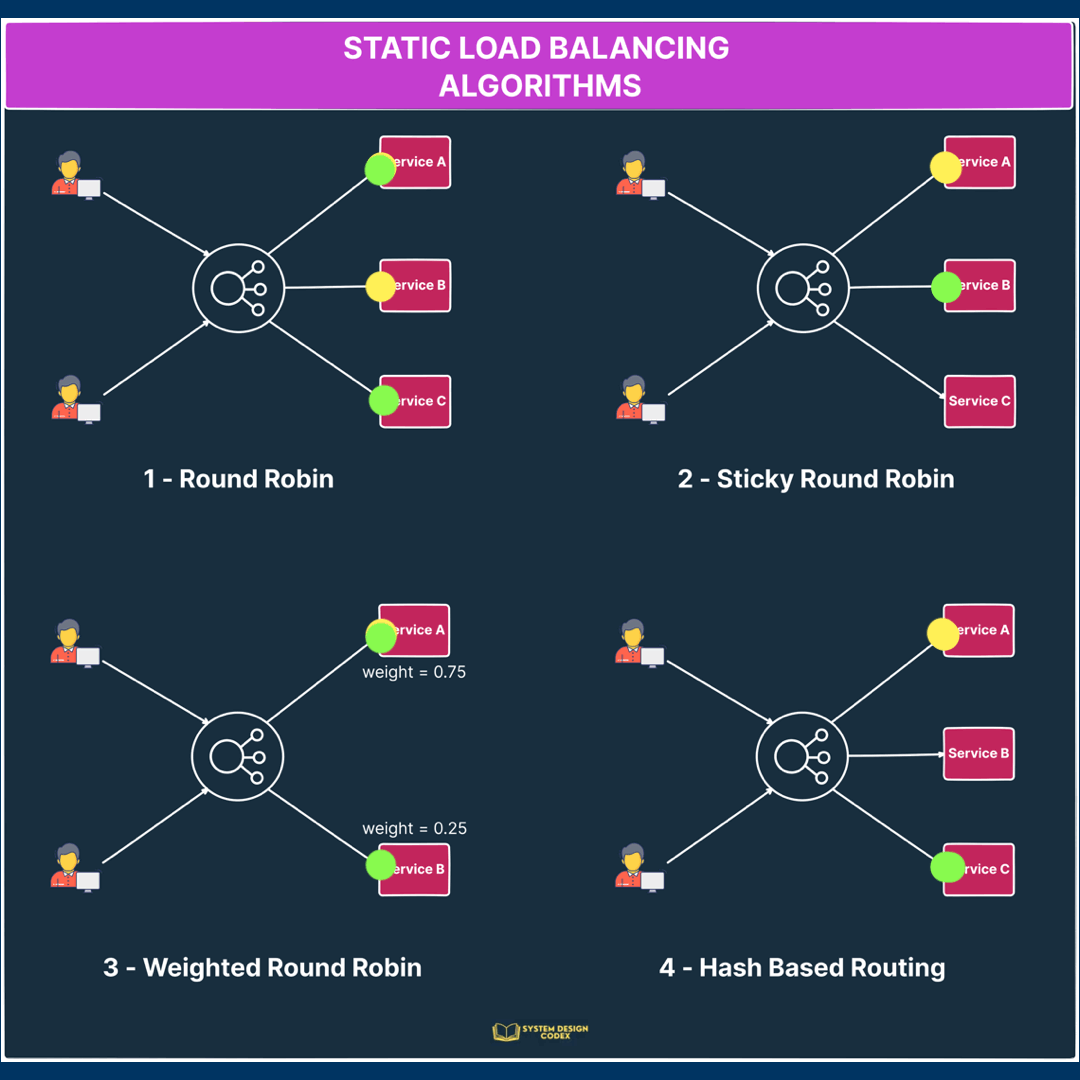
1 – Round Robin
Requests are distributed sequentially across a group of servers.
The main assumption is that the service is stateless because there’s no guarantee that subsequent requests from the same user will reach the same instance.
2 – Sticky Round Robin
This is a better alternative to round-robin since subsequent requests from the same user go to the same instance.
Depending on the use case, this can be a desirable quality for load balancing.
3 – Weighted Round Robin
In this algorithm, each server instance gets a specific weight value.
This value determines the proportion of traffic that will be directed to the particular server.
Servers with higher weights receive a larger share of the traffic while servers with lower weights receive a smaller share.
For example, if server instance A has a weight of 0.75 and instance B has a weight of 0.25, server A will receive thrice as much traffic as instance B.
That’s a super-useful approach when different servers have different capacity levels and you want to assign traffic based on capacity.
4 – Hash
The hash algorithm distributes requests based on the hash of a particular key value.
Here, the key can be something like the combination of source and destination IP addresses.
See the below illustration for how the static load balancing algorithms work:
Dynamic Load Balancing Algorithms
Dynamic load balancing depends on some property that keeps on changing to make routing decisions.
Let’s look at a couple of such algorithms.
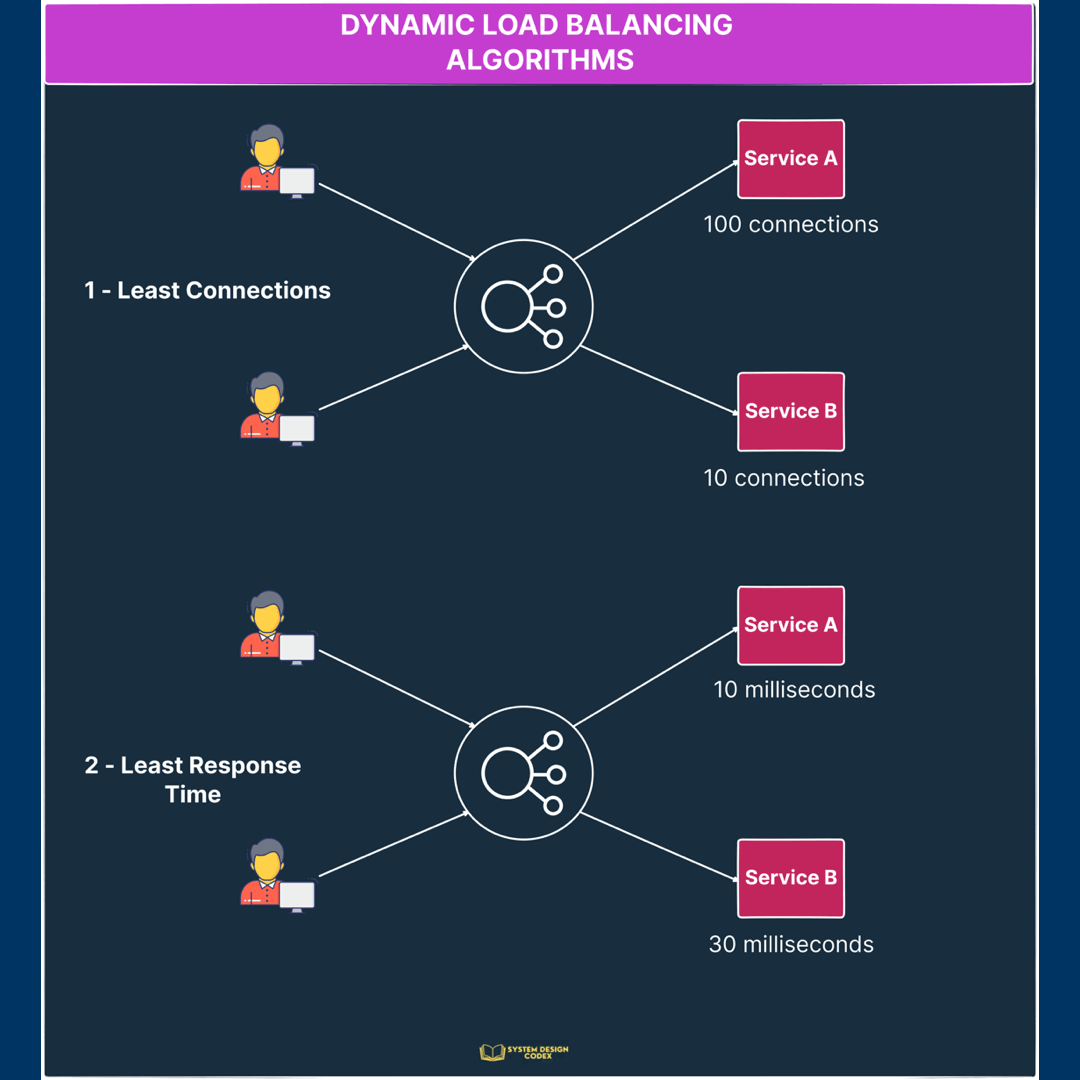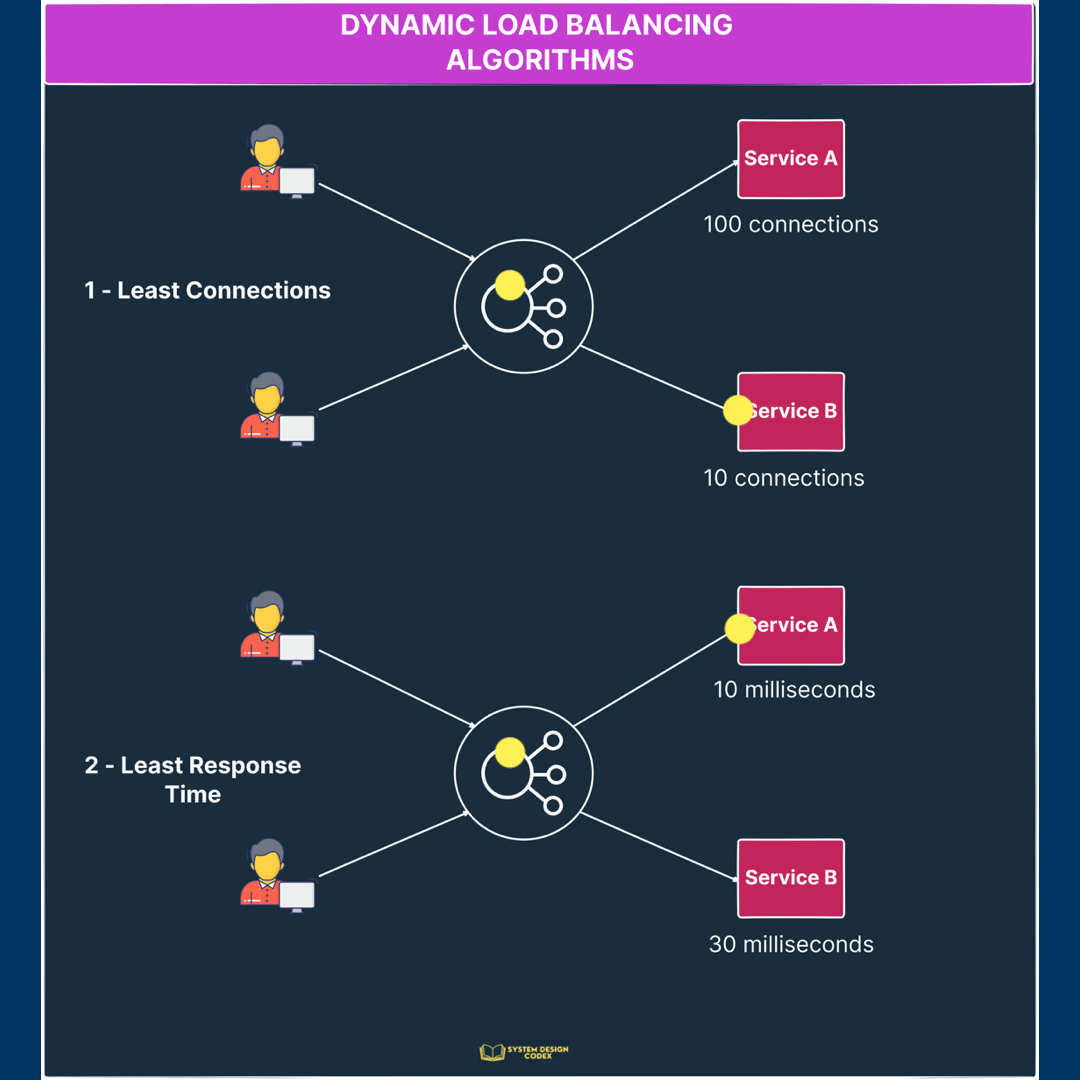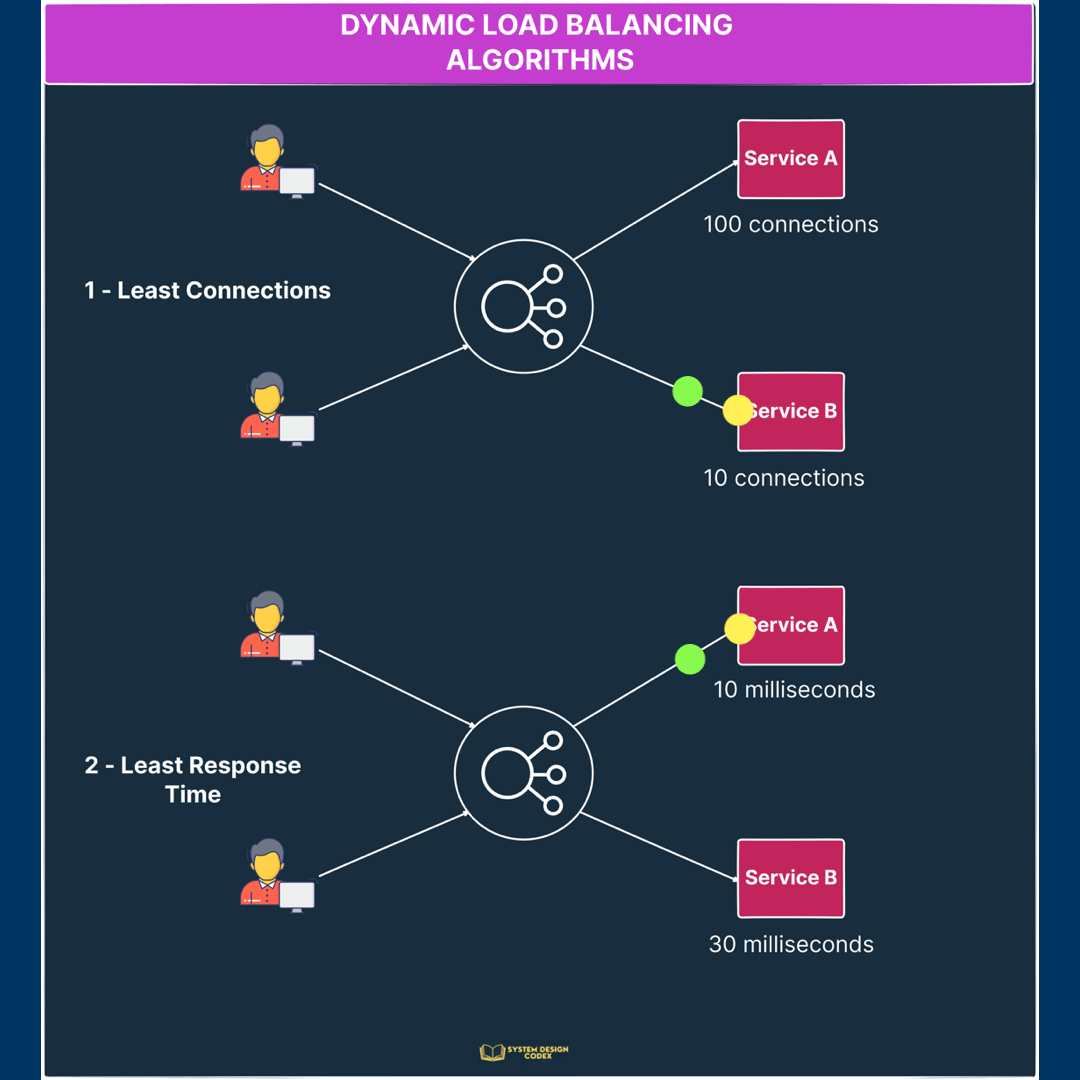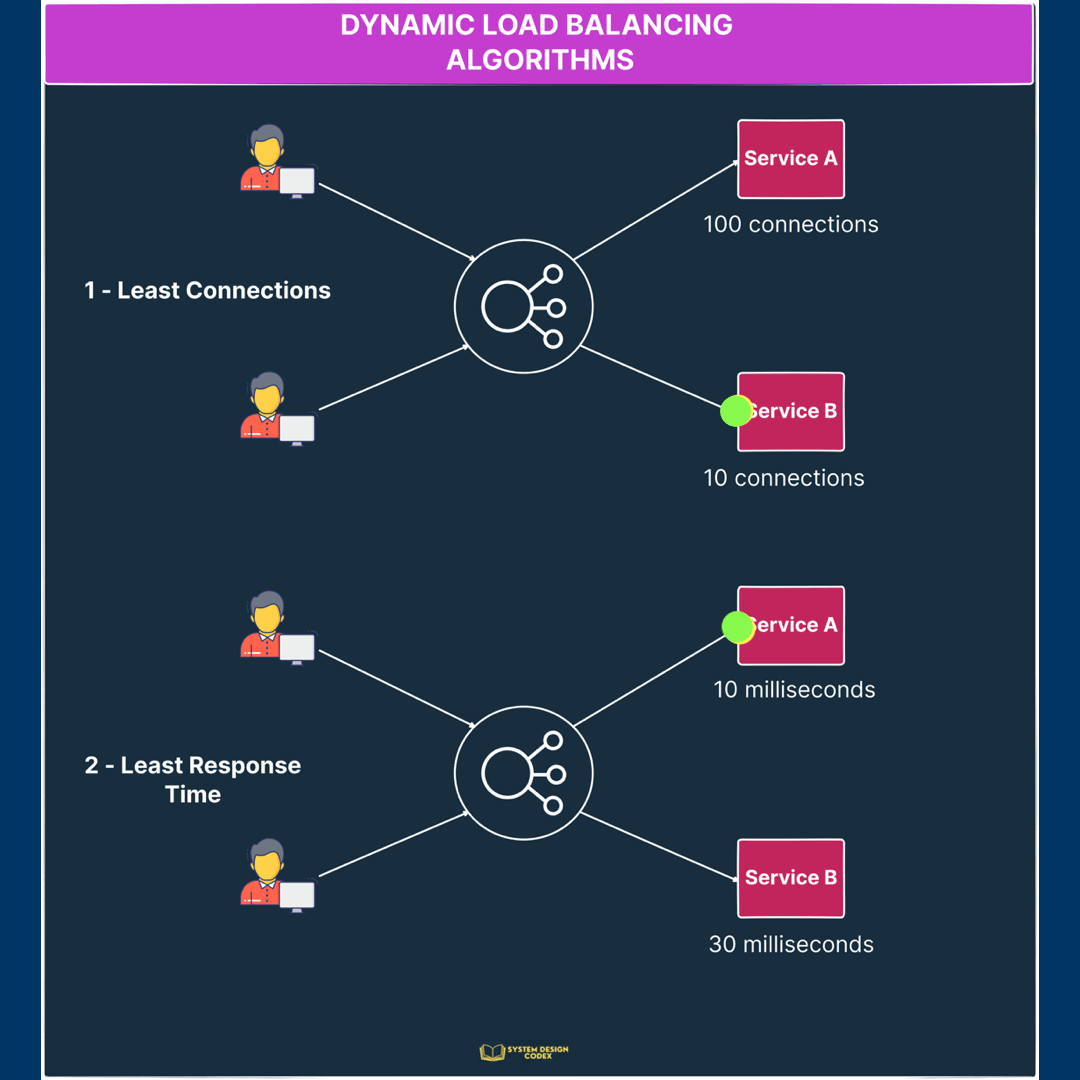
1 – Least Connections
In this algorithm, a new request is sent to the server instance with the least number of connections.
Of course, the number of connections is determined based on the relative computing capacity of a particular server.
So, server instances with more resources can support more connections as compared to instances with low resources.
2 – Least Response Time
In this case, the load balancer assigns incoming requests to the server with the lowest response time in order to minimize the overall response time of the system.
This is great for cases where response time is critical and you want to ensure that the request goes to an instance that can provide a quick response.
Check out the below illustration to see the dynamic load balancing algorithms in action.
Making Load Balancers Highly Available
“What if the Load Balancer goes down?”
This is a common sentiment I’ve seen come up during design discussions.
Generally, the question is hand-waived by saying that the cloud provider will take care of it.
And that’s mostly true.
Modern cloud systems have reached a point where developers need not concern themselves with the ins and outs of maintaining infrastructure pieces like the load balancer.
These infra pieces are treated as services and it’s the job of the service provider to make sure that things are working fine.
But it can be a good exercise to consider what a high availability load balancer setup looks like.
Here’s a diagram that attempts to show the big picture:
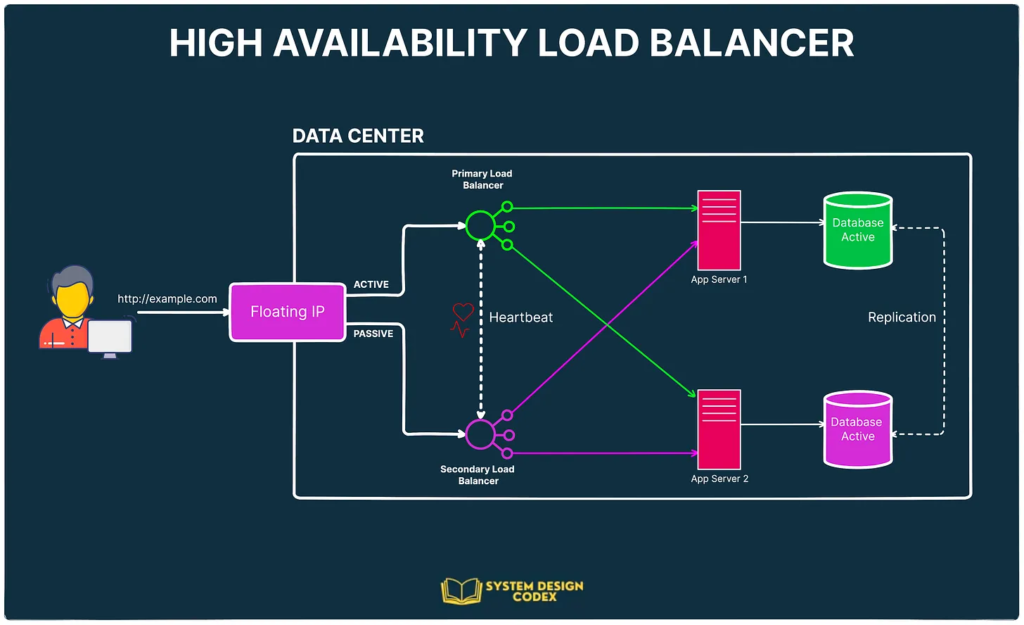
Ultimately, when you talk about a high-availability load balancing setup, what you mean is that the load balancer should not become a single point of failure (SPOF).
And how do we remove a single point of failure?
Of course, by investing in redundancy.
In the above example, we have multiple load balancers (one active and one or more passive) behind a static IP address. This static IP address can be remapped from one server to another.
When a user accesses your website, the request goes through the floating IP address to the active load balancer.
If that load balancer fails for some reason, the failover mechanism will detect it and automatically reassign the IP address to one of the passive servers that will take over the load balancing duties.
Note that here we are only talking about HA setup for load balancer and not the other parts such as databases and application servers.
Conclusion
Finally, having discussed so much about load balancing, it’s time to answer the money question.
“Is Load Balancing really worth it?”
For me, it’s a definite YES if you’re building a serious system where managing availability and performance is important.
Few important reasons for the same:
- You can’t have seamless horizontal scalability without a load balancer distributing the traffic between multiple instances.
- You can’t support high availability in the absence of a load balancer to make sure the request is routed to the best possible instance.
- Load balancers also prevent a single server instance from getting overwhelmed, thereby improving the performance.
In this post, I have attempted to touch upon the most important aspects of a Load Balancer. These are things that you must know before dealing with a Load Balancer in your own application.
If you have any comments or queries about this, do mention them in the comments section below.
Also, if System Design topics like this interest you, consider subscribing to my free weekly newsletter.
0 Comments